September 21, 2025

TL;DR
Before diving deep into the benchmarks, let us set the stage for the new IPhone 17 lineup by reviewing how Apple positioned their new product.
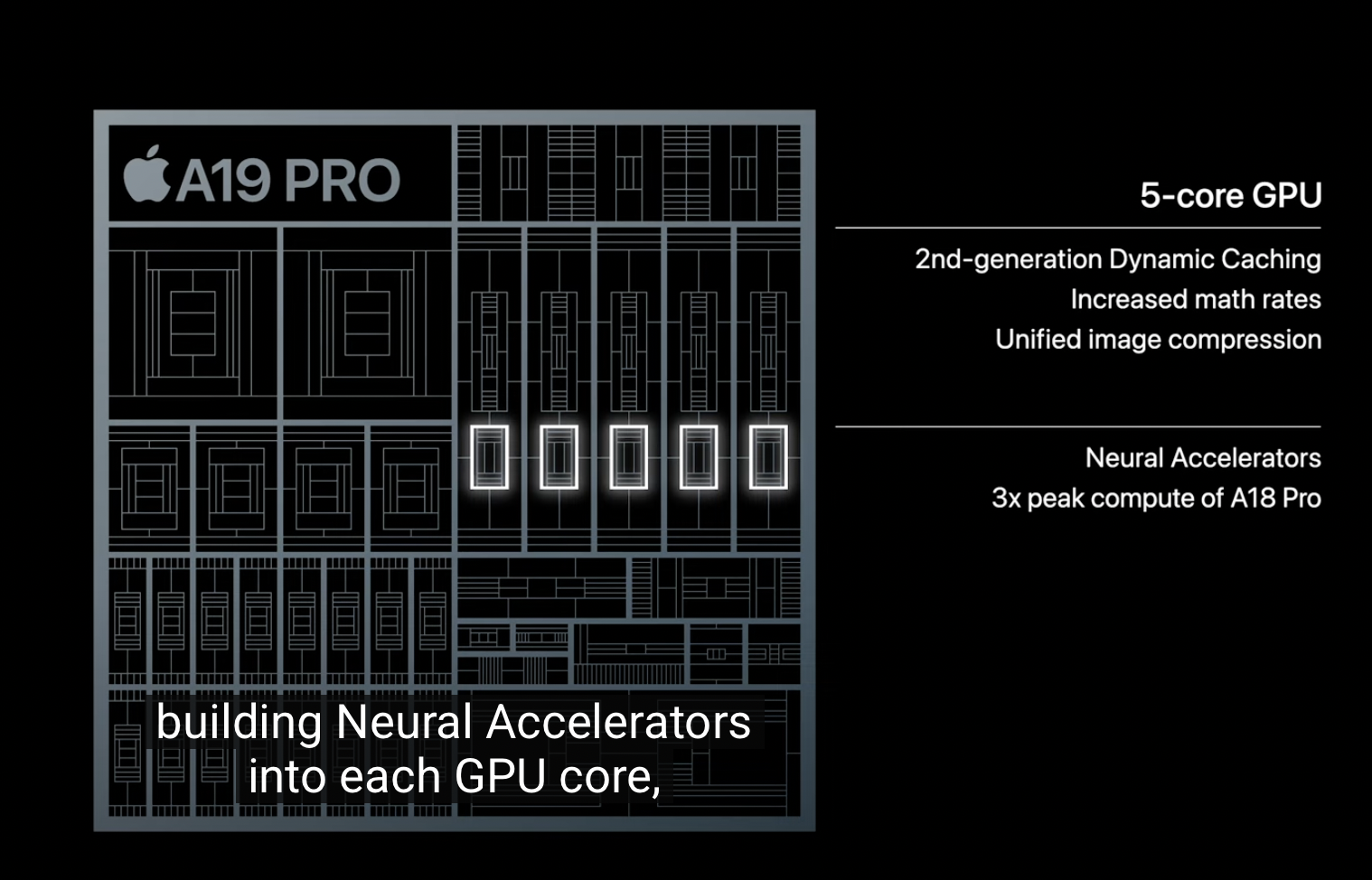
Keynote excerpt: "...The other major update to our GPU is around AI. We have been at the forefront of AI acceleration since we first introduced the Neural Engine eight years ago. We later brought machine learning accelerators to our CPUs. And while our GPU has always been great at AI compute, we're now taking a big step forward. Building neural accelerators into each GPU core. Delivering up to 3 times the peak GPU compute of A18 Pro. This is MacBook Pro levels of Compute in an iPhone. Perfect for GPU-intensive AI workloads..."
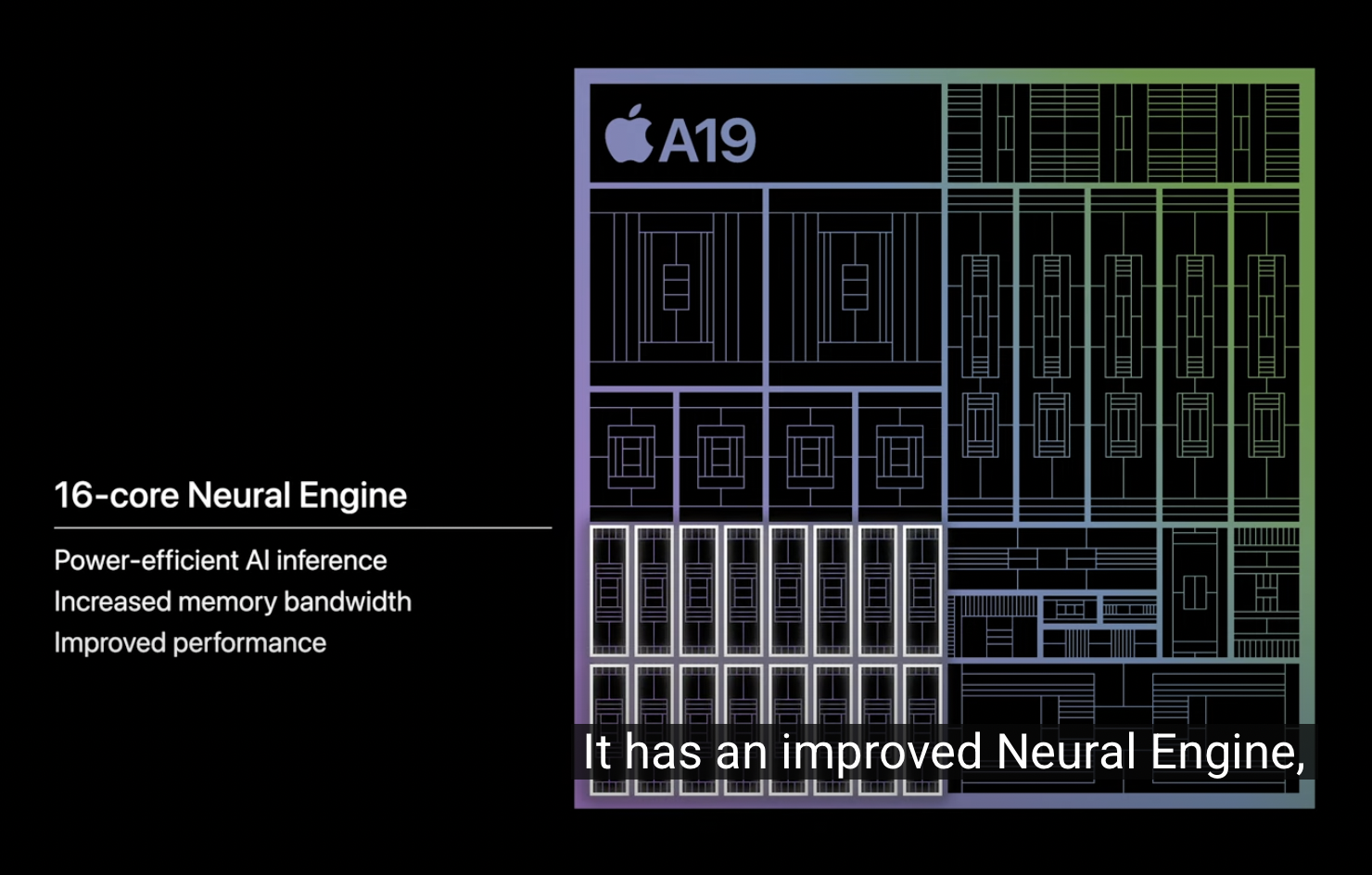
Keynote excerpt: "...It has an improved Neural Engine tailored to power incredible on-device performance for Apple Intelligence. Combined with increased memory bandwidth of A19, on-device generative and large language models will run even faster..."

Keynote excerpt: "...We meticulously manage power and surface temperature to make sure iPhone 17 Pro and iPhone 17 Pro Max always deliver exceptional performance while remaining comfortable to hold...This efficiently moves heat away from the components, allowing for higher sustained performance. The vapor chamber directs heat strategically through the system...20 times greater than the titanium we previously used..."
We designed performance benchmarks to put these marketed improvements to the test. Specifically, we tested the improved peak GPU and Neural Engine throughput with burst workloads involving large Transformers, using a mix of prompt processing (compute-bound encoding) and token generation (bandwidth-bound decoding) components. Then, we tested thermal behavior with sustained workloads involving the same large Transformer models. The benchmark app and input data are linked below for reproducibility. Shoot us a note at support@argmaxinc.com if you have questions or comments.
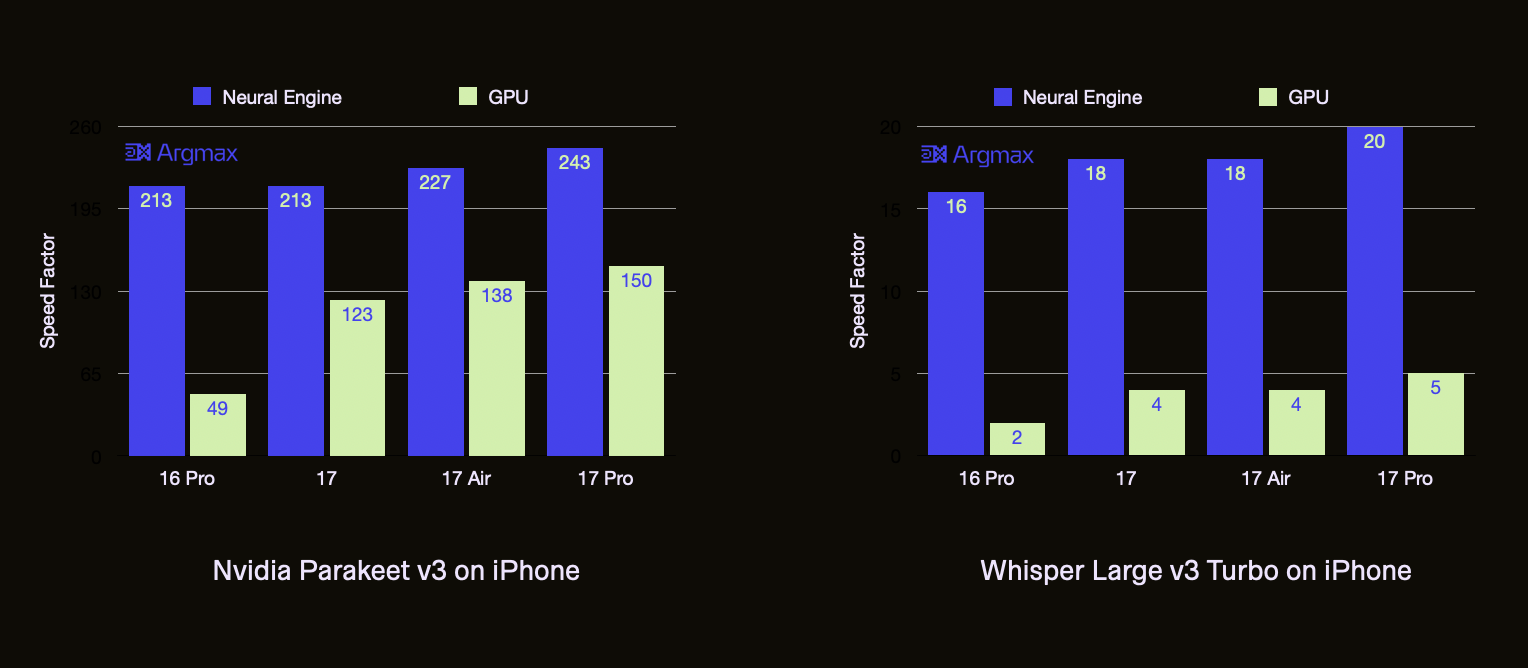
This workload requires processing a 10-minute audio file with Nvidia Parakeet v3, a frontier speech-to-text model, using the Argmax Playground app.
This workload on Argmax Playground achieves 15+ Tflops/s on the iPhone 16 Pro Neural Engine, near-peak utilization of the 17.5 Tflops/s theoretical max throughput with float16 precision. We have not historically focused on benchmarking the GPU performance because it simply was not competitive in terms of speed and power efficiency, as can be seen in the iPhone 16 Pro, but the iPhone 17 lineup made the GPU relevant as the results below clearly demonstrate.
Speed Factor, the number of seconds of audio transcribed per second of processing time, is the primary benchmark metric for this workload. On iPhone 16 Pro, the Neural Engine is 4.3x faster than the GPU for Nvidia Parakeet v3, a ConvNet-Transformer hybrid model with 0.6 billion parameter. The iPhone 17 lineup improved on the iPhone 16 Pro GPU performance by 2.5-3.1x while this number was only 1-1.15x for the Neural Engine. This workload is heavily bottlenecked by the audio encoder component due to an asymmetric encoder-decoder architecture which makes it a good fit for testing peak compute throughput as opposed to memory bandwidth improvements.
We also tested another popular speech-to-text model: Whisper Large v3 Turbo. This is a pure Transformer with 1 billion parameters and a balanced encoder-decoder latency. †
This workload requires transcribing the first 30 minutes of this YouTube video in real-time with sub-second latency using Nvidia Parakeet v3 on the Argmax Playground app. This workload is continuously dissipating heat and drawing energy from the battery at near peak compute utilization, making it an ideal benchmark for testing the new cooling system in the iPhone 17 lineup.
For the video below:
The results are self-evident: iPhone 17 Pro's new cooling system is highly effective in dissipating heat from this continuous heavy inference workload, even on the GPU.
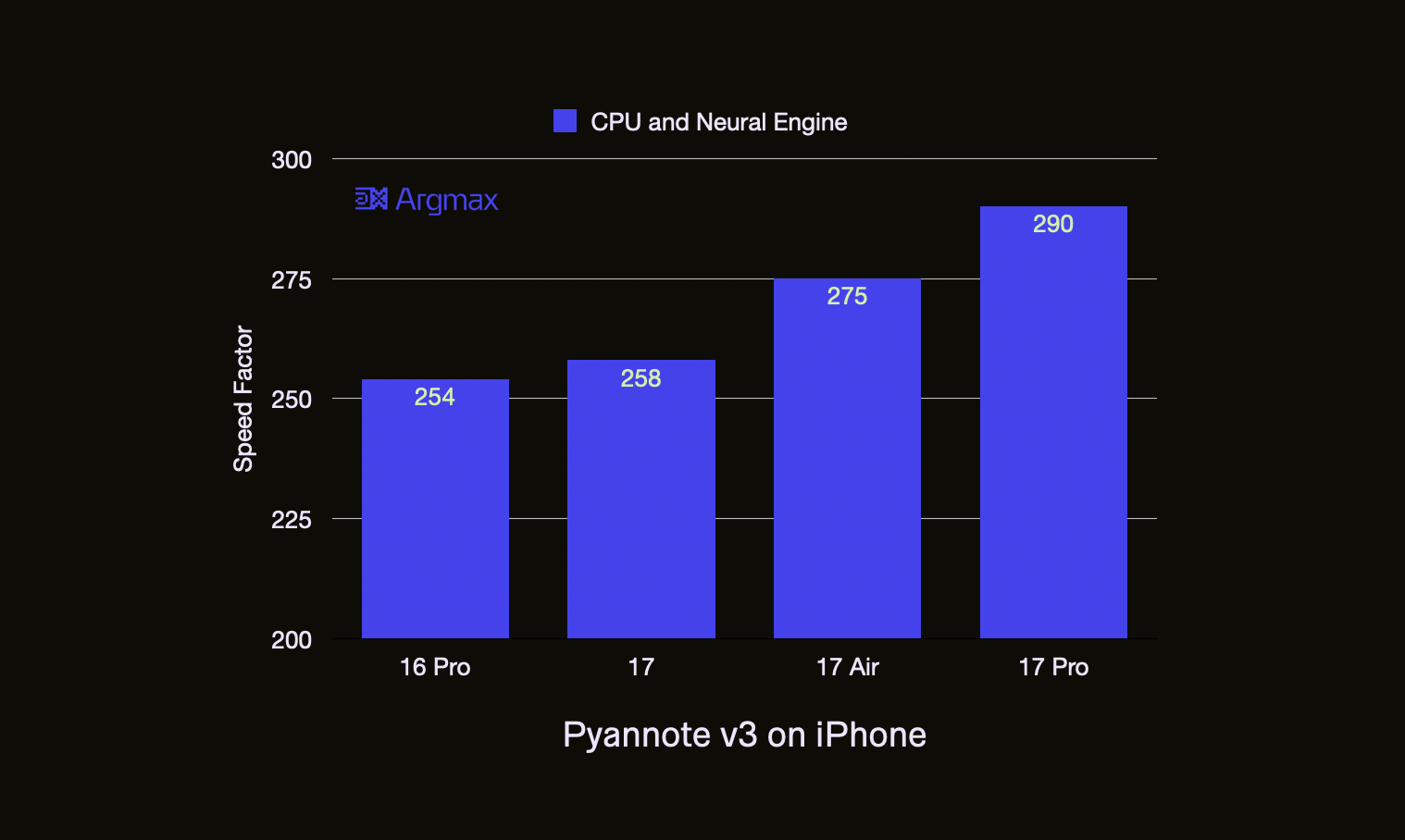
This workload requires processing a 10-minute audio file with pyannote v3, an open-source speaker diarization model, using the Argmax Playground app. This model is a ConvNet-LSTM hybrid model with 0.01 billion parameters. Argmax Playground runs this model on the CPU and the Neural Engine. The iPhone 17 lineup achieves a 1.01-1.15x speedup compared to iPhone 16 Pro.
Apple has significantly increased the priority for achieving market-leading performance for large Transformer inference workloads with the A19 and A19 Pro chips in the iPhone 17 lineup. Most of these improvements come "out-of-the-box" with iOS 26.
Despite some progress, achieving peak performance on the Neural Engine still feels like black magic to most developers. On the other hand, the GPU is directly programmable with Metal and frameworks like MLX make it highly accessible to deploy popular models with near-peak utilization on Apple Silicon GPU. This is why the Neural Accelerators in GPU announcement is a very promising direction for highly accessible high-performance inference on Apple Silicon.
We have observed up to 3.1x speed-up from iPhone 16 Pro to the iPhone 17 lineup on the GPU. The marketed improvement was up to 4x and the remaining improvements may come as the underlying Apple inference frameworks, i.e. MPSGraph is the GPU backend for Core ML, improve. MLX developers announced that they will start adding support for these new cores in the coming weeks..
Nonetheless, the Apple Foundation Model - a Transformer with 3 billion parameters - is still deployed on the Neural Engine for several good reasons: top energy-efficiency to maximize battery life, natively accelerated advanced compression techniques and higher peak throughput even after the A19 Pro updates to the GPU.
While supporting Enterprise customers at Argmax, we have realized even more reasons that the Neural Engine will stay the clear choice for on-device inference at scale:
We have noticed an alternating pattern where Apple improves the GPU and Neural Engine in alternating years. We are extremely excited to see what Apple's (presumed) A20 will bring to the Neural Engine.
If you want to integrate these state-of-the-art speech-to-text and speaker diarization capabilities into your application, you can get started with Argmax Pro SDK that powers the Argmax Playground app used in these benchmarks today by signing up for a 14-day trial on our Platform.
† Note that the Whisper Large v3 Turbo model is weight-compressed with a format that is natively accelerated only by the Neural Engine, which leads to an even wider gap in performance between the Neural Engine and the GPU. On iPhone 17 Air, the same model without compression runs at a Speed Factor of 10 (not plotted), up from 4. This is at the cost of 4x higher memory consumption. For the curious, we describe this technique in our ICML 2025 presentation.
FOLLOW US