June 20, 2025

TL;DR
↑: Higher is better
Speed factor indicates the number of seconds of input audio processed by the transcription system in one second of wall-clock time, e.g. A speed factor of 60 means that a system can process 1 minute of audio in 1 second.
All results are computed on an M4 Mac mini running macOS 26 Beta Seed 1. Apple results are obtained through this open-source benchmark script and can be easily reproduced. Argmax results are obtained in our Playground app on TestFlight and can be reproduced even more easily.
This is the Word Error Rate (WER) metric computed on a random 10% subset of the earnings22 dataset, consisting of ~12 hours of English conversations from earnings calls with analysts. The reason for picking this dataset is that Apple mentions long-form conversational speech as the primary improvement with their new SpeechTranscriber model.
The Error Rate results from above provide high-level insights into the speech-to-text accuracy of Apple and Argmax systems on general vocabulary. However, many real-world use cases disproportionately rely on accuracy for important known keywords instead.
The following benchmark demonstrates the keyword recognition accuracy of Apple SpeechAnalyzer (iOS 26), Apple SFSpeechRecogizer (pre-iOS 26) and Argmax SDK. Keywords are defined as people, company and produt names that occur in the earnings22 dataset. Please see this GitHub repository for details.
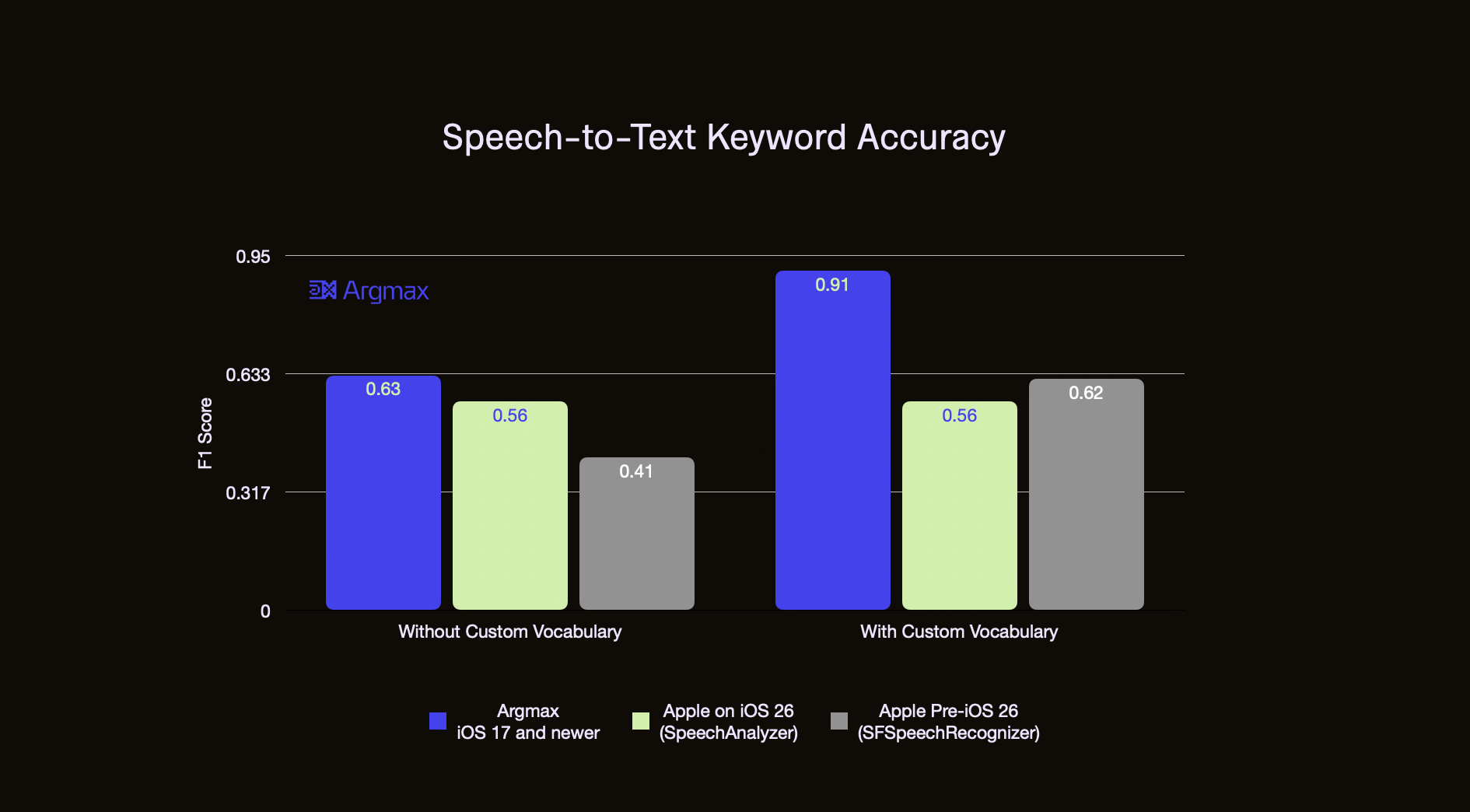
Notably, Apple's new SpeechAnalyzer (iOS 26) API lacks the Custom Vocabulary feature that lets developers improve accuracy on known-and-registered keywords while Apple's older SFSpeechRecognizer API (pre-iOS 26) has this feature and surpasses their new API in accuracy.
Argmax with Custom Vocabulary surpasses both by a significant margin and even matches top cloud APIs in keyword recognition accuracy.
We were slightly disappointed to see that Apple’s model still requires a download and does not come pre-installed with iOS or macOS. However, if Apple SpeechAnalyzer is widely adopted, a newly installed app will find that the model was previously downloaded by another app, including Apple’s first-party apps, on the same device, and skip the download! This removes a significant obstacle for on-device deployment: the latency from app install to first inference, which is dominated by model download time.
For this purpose, Argmax will integrate Apple SpeechAnalyzer so that Argmax WhisperKit and Argmax SDK users may also benefit from a pre-downloaded model while their Argmax model is being downloaded for them.
Browse Apple SpeechAnalyzer documentation.
Start with Argmax WhisperKit on GitHub.
Get access to Argmax SDK.
FOLLOW US