November 19, 2025
TL;DR
Clean audio recordings of casual conversations without any names or jargon are easy to transcribe. In fact, most speech-to-text systems today do an almost perfect job under these conditions. However, most systems break under realistic in-the-wild settings, such as the one below. Custom Vocabulary works by registering a list of contextual keywords to the transcription system in order to enable a dedicated "keyword search" .
Key differentiators of Argmax Custom Vocabulary compared to similar features in commercial cloud APIs include:
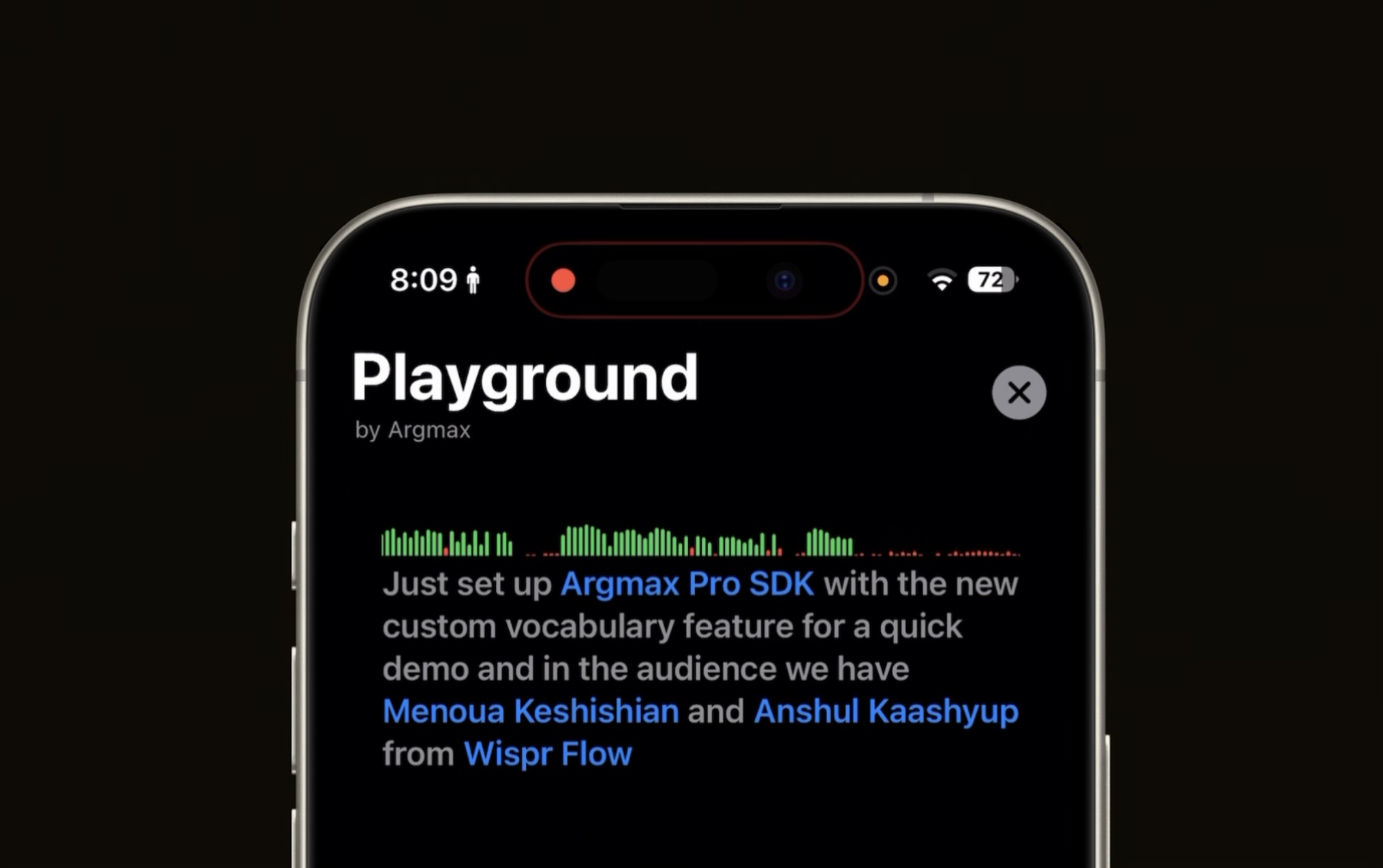
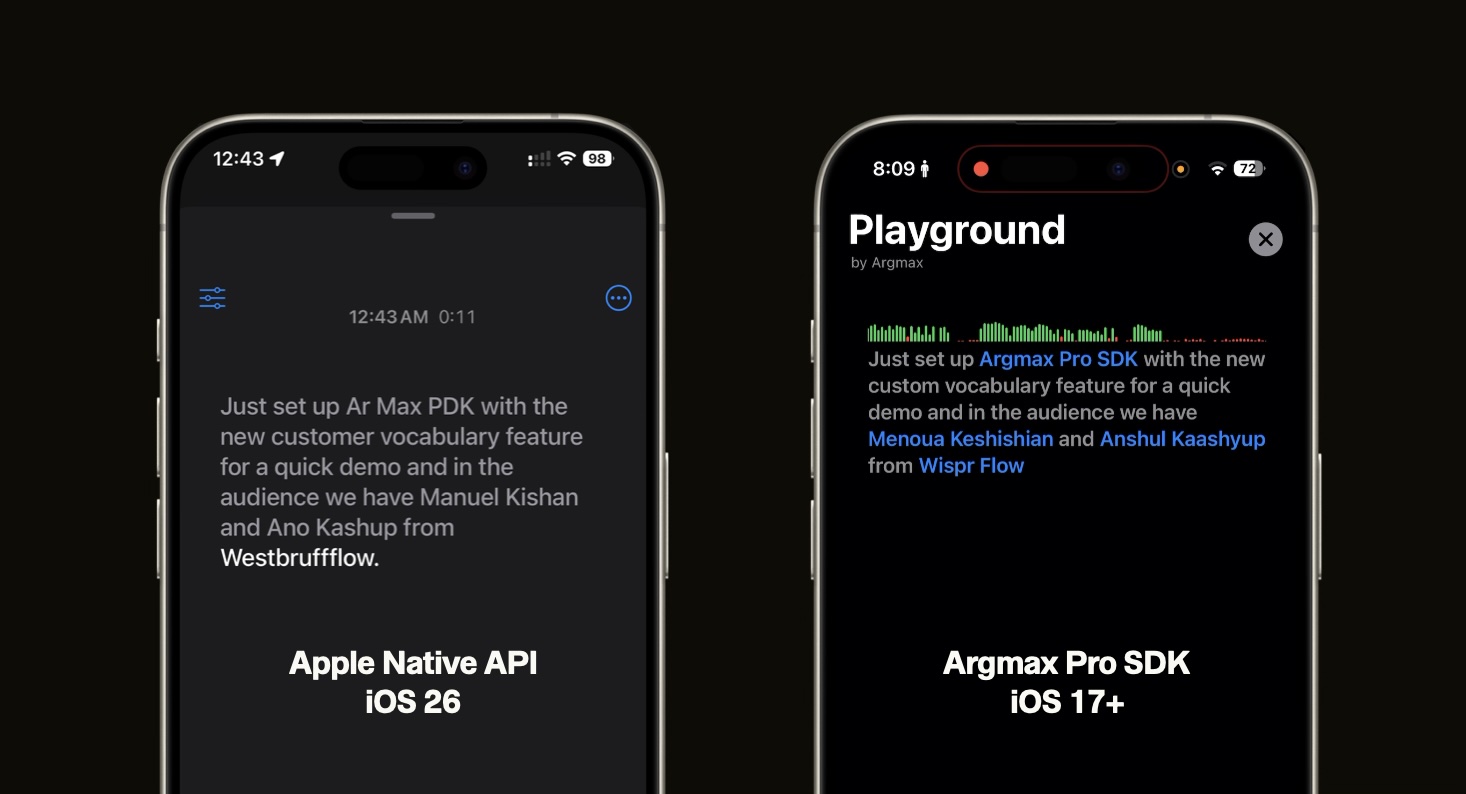
How can developers determine the contextual keywords to register in the vocabulary? Here are just a few examples:
Achieving high accuracy on names and jargon makes all the difference between toy utility software and critical infrastructure for high-stakes use cases such as AI medical scribes, virtual meeting transcription and even personal dictation software.
To the best of our knowledge, there is no publicly available dataset to measure speech-to-text accuracy for keyword recognition, e.g. for proper name spelling. For this purpose, we have reannotated the popular earnings22 dataset with people, company and product names as keywords. In the first version of this dataset, we have curated ~1000 audio clips, each 15 seconds long, that contain at least one name. We have reviewed each sample manually which led to many corrections of the original ground-truth transcript annotations because challenging parts of the audio were annotated as inaudible and many names were incorrectly annotated. After manually verifying and fixing the names, including making LinkedIn searches to cross-reference people and company names, we have come up with an extremely high-quality test set. On this set, the accuracy of Argmax Pro SDK, as measured by the F1-score, improves from 64% to 92% when the new Custom Vocabulary feature is activated!
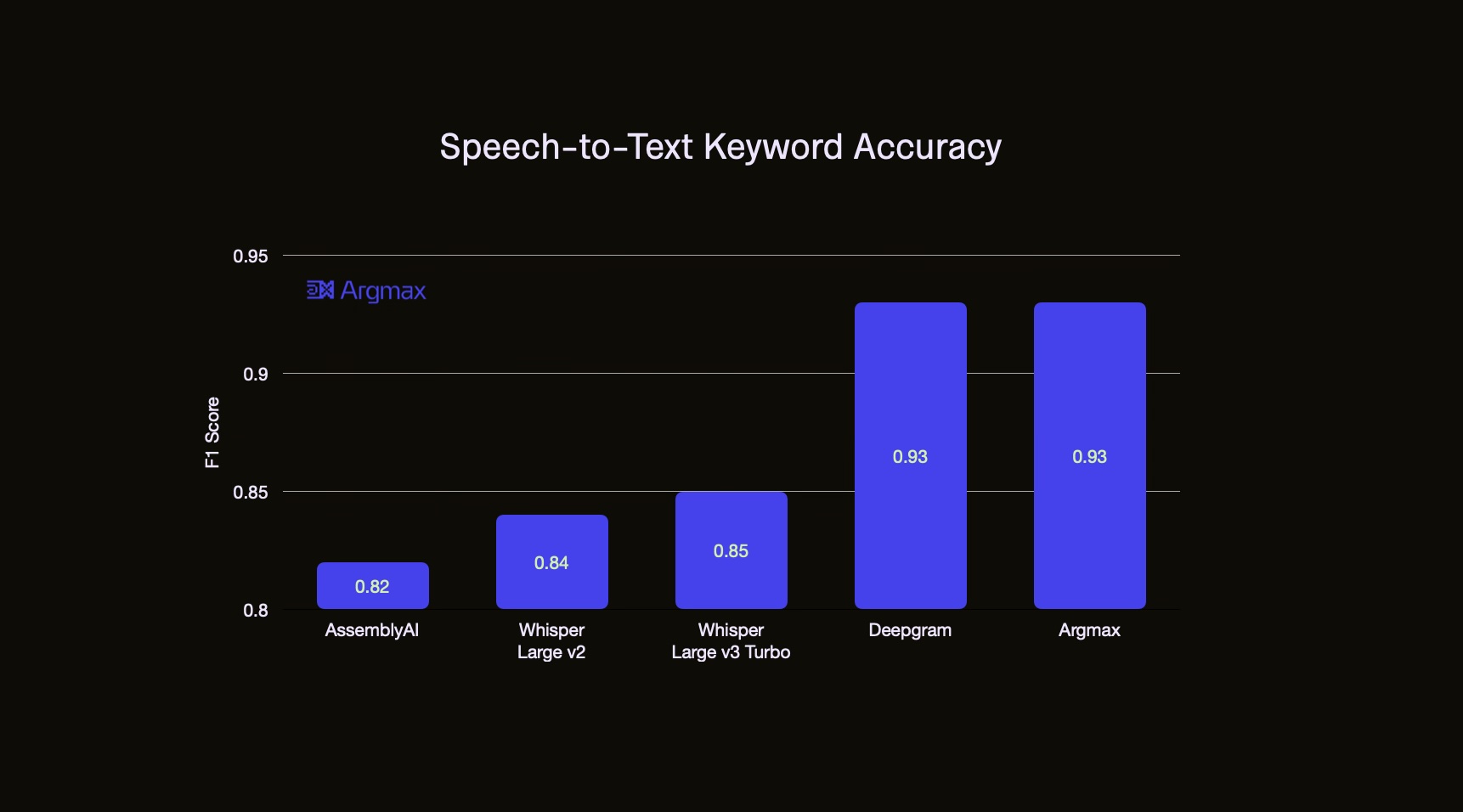
As shown above, the keyword accuracy of Argmax significantly surpasses AssemblyAI, Whisper Large v2 (OpenAI API) and Whisper Large v3 Turbo (OpenAI OSS) and matches Deepgram. Argmax has improved from 0.88 to 0.92 from October to November and will continue to improve in the next few months.
This feature has been available in alpha testing for the past week, and several customers have already shipped with the stable version today! If you are a superwhisper user, update to 2.6.2 to get Custom Vocabulary added to the Nvidia Parakeet models powered by Argmax Pro SDK!
FOLLOW US